

Replicating Data in Distributed Systems
Replicating Data in Distributed Systems
Chapter 5 of Designing Data Intensive Applications: Replication

Welcome to the 10% Smarter newsletter. I’m Brian, a software engineer writing about tech and growing skills as an engineer.
If you’re reading this but haven’t subscribed, consider joining!
Hey! We’ve gone through the storage and dataflow of data focusing on a single machine, but most online systems have to use distributed machines to scale. One reason for this is to replicated the data.
Replication is the process of copying data to multiple machines. This increases read throughput, availability, ands keeps data geographically close to users. Every node that keeps a copy of data is a replica.
To do replication, there are three approaches, Leader-Based Replication, Multi-Leader Replication, and Leaderless Replication. We’ll cover all three today.
Leader-Based Replication
Leader-Based Replication is a strategy to ensure data on all replicas are the same. The strategy is:
Only the leader can accepts writes.
Followers read off a replication log and apply all writes in the same order that they were processed by the leader.
A client can query the leader and any of its followers for read requests.
Replica followers are read-only and writes are only accepted by the leader. This approach is used by Postgres, MySQL, and MongoDB.
This replication can be done synchronously or asynchronously. Synchronous replication requires the leader to wait for acknowledgement from at least one follower the data has been successfully replicated while in asynchronous replication, the leader does not have to wait.
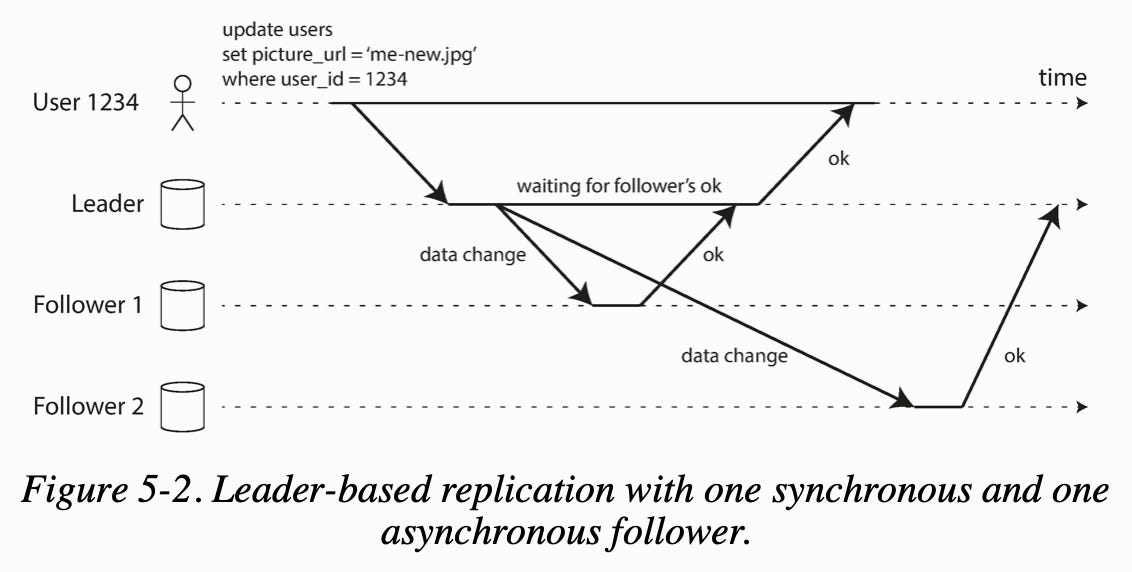
The advantage of synchronous replication is that a follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader. The disadvantage is that if a synchronous follower doesn't respond, the write cannot be processed.
Replication can also be semi-synchronous, where one follower is synchronous and the others are asynchronous.
Often, leader-based replication is asynchronous. Writes are not guaranteed to be durable, but the leader can continue processing writes. The process to set up followers with a copy of the leader’s data is as follows:
Take a snapshot of the Leader's database.
Copy the snapshot to the Follower Node.
Follower requests data change that has happened since the snapshot was taken.
Once the follower has processed the backlog of data changes since the snapshot, it is now caught up.
Node Outages and Leader Failover
If a follower fails, it can use catchup recovery: the follower will keep a local log of data changes it has received from the leader. If the follower node fails and recovers, it will compare its log to the leaders log and apply all data changes.
If the leader fails, failover occurs and another node is promoted to new leader. Failover can be done manually or automatically.
Automatic failover consists of:
Determining that a leader has failed. If a node does not respond and times-out in an interval, it is considered dead.
Choosing a new leader. This is done in an election process where the most up-to-date candidate replica becomes leader.
Reconfiguring the system to use the new leader. The system needs to ensure that the old leader becomes a follower and recognizes the new leader.
Several things can go wrong in failover. These include:
If asynchronous replication is used, the new leader may have received conflicting writes in the meantime.
Discarding writes is especially dangerous if other storage systems outside of the database need to be coordinated with the database contents. This has occurred at GitHub with an auto-incrementing counter used as a MySQL primary key and a Redis store key. The old leader failed and some writes were not processed. The new leader begin using some primary keys which have already been assigned in Redis, leading to inconsistencies in the data.
It could happen that two nodes both believe that they are the leader (split brain), leading to data to be likely to be lost or corrupted. GitHub also had an issue where a mechanism to shut down one node if two leaders are detected shut down both nodes.
Knowing the right time before the leader is declared dead. Too long, it means a longer time to recovery in the case where the leader fails. Too short, we can have unnecessary failovers which can make the situation worse if the system is already struggling with high load or network problems.
Replication Logs
To perform the replication, followers will read from a replication log from the leader. There are a couple of ways of doing this.
Statement-based replication: The leader logs every statement and sends it to its followers (every INSERT, UPDATE or DELETE).
Write-ahead log (WAL) shipping: The log is an append-only sequence of bytes containing all writes to the database. The leader can send it to its followers.
Logical (row-based) log replication: This logs the changes that have occurred at the granularity of a row. This means:
For an inserted row, the log contains new values of all columns.
For a deleted row, the log contains enough information to identify the deleted row, typically the primary key.
For an updated row, it contains enough information to identify the updated row, and the new values of all columns.
Trigger-based replication: This involves handling replication within the application code. It provides flexibility in dealing with things like: replicating only a subset of data, conflict resolution logic, replicating from one kind of database to another, etc.
Eventual Consistency and Consistency Levels
If an application reads from an asynchronous follower, it may see outdated information. This state is known as eventual consistency. To achieve better consistency, there are stronger consistency levels that can be used.
Reading Your Own Writes: also known as read-your-writes consistency, guarantees if a user reloads the page, they will always see any updates they submitted themselves. A simple implementation is when reading something that the user may have modified, read it from the leader instead of follower.

Monotonic reads: Because of followers falling behind, it's possible for a user to see things moving backward in time (reading from a stale follower). Monotonic reads prevents this by making sure that each user always makes their reads from the same replica. The replica can be chosen based on a hash of the user ID.
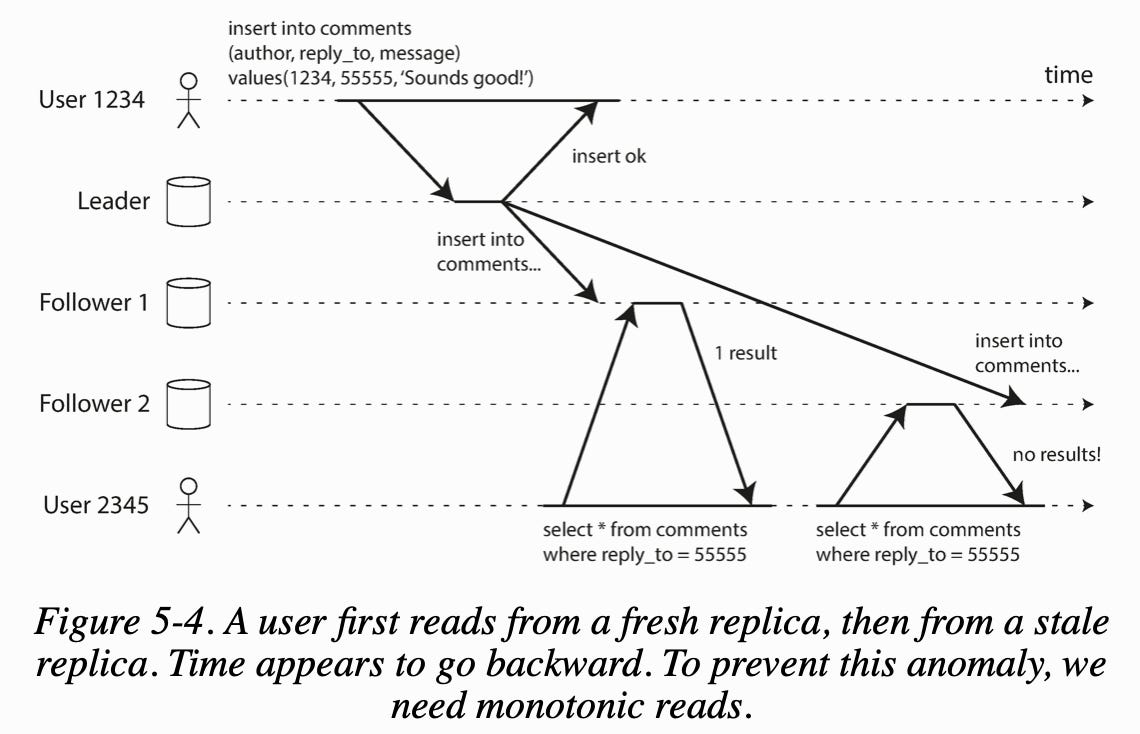
Consistent prefix reads: guarantees that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order. A solution is to make sure any writes casually related to each other are written to the same partition.

Now let’s explore Multi-Leader Replication.
Multi-Leader Replication
Leader-based replication has one major downside: there is only one leader, and all writes must go through it. Multi-leader replication allows more than one node to accept writes (active/active replication) where each leader simultaneously acts as a follower to the other leaders.
This may be used in multi-datacenter operations, clients with offline operations, and collaborative editing.
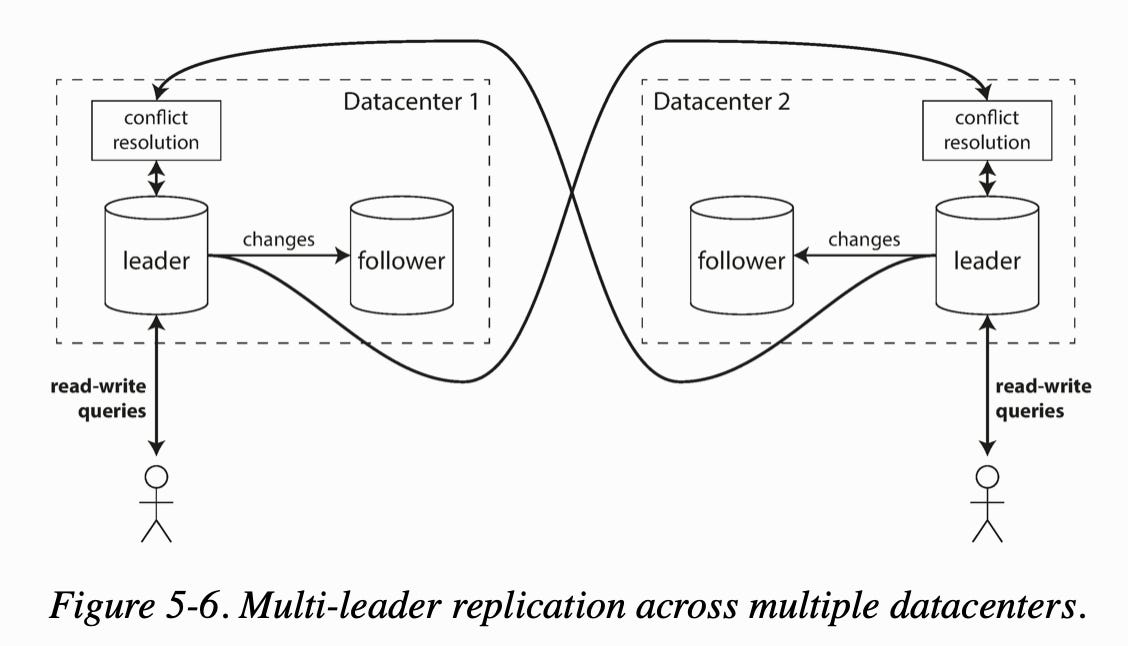
Multi-leader replication is often considered dangerous and should avoided if possible. It's common to fail on subtle configuration pitfalls. Auto-incrementing keys, triggers and integrity constraints can be problematic. Multi-leader replication also have the big disadvantage that write conflicts can occur, which requires conflict resolution.
Conflict Resolution
The simplest strategy for dealing with conflicts is to avoid them. If all writes for a particular record go through the same leader, then conflicts cannot occur.
A second strategy is converging toward a consistent state. One way is Last Write Wins (LWW) picking the write with the highest id timestamp. This however is prone to data loss.
Finally, you can use custom conflict resolution by the client. This can be done at write or read by storing all conflicting writes.
Now, let’s explore Leaderless Replication.
Leaderless Replication
In Leaderless Replication, no write leader is used. All replicas can accept writes from clients. The client will send all writes and reads to all replicas where the client may get different read responses. A quorum is required to confirm a write is successful and to get the most up-to-date data on read. Version numbers are also used to prevent stale reads.
Leaderless replication may be appealing for use cases that require high availability, low latency, and can tolerate occasional stale reads.
In leaderless replication, if an unavailable node come back online, it has two different mechanisms to catch up:
Read repair. When a client detect any stale responses, write the newer value back to that replica.
Anti-entropy process. There is a background process that constantly looks for differences in data between replicas and copies any missing data from one replica to the other.
Quorums
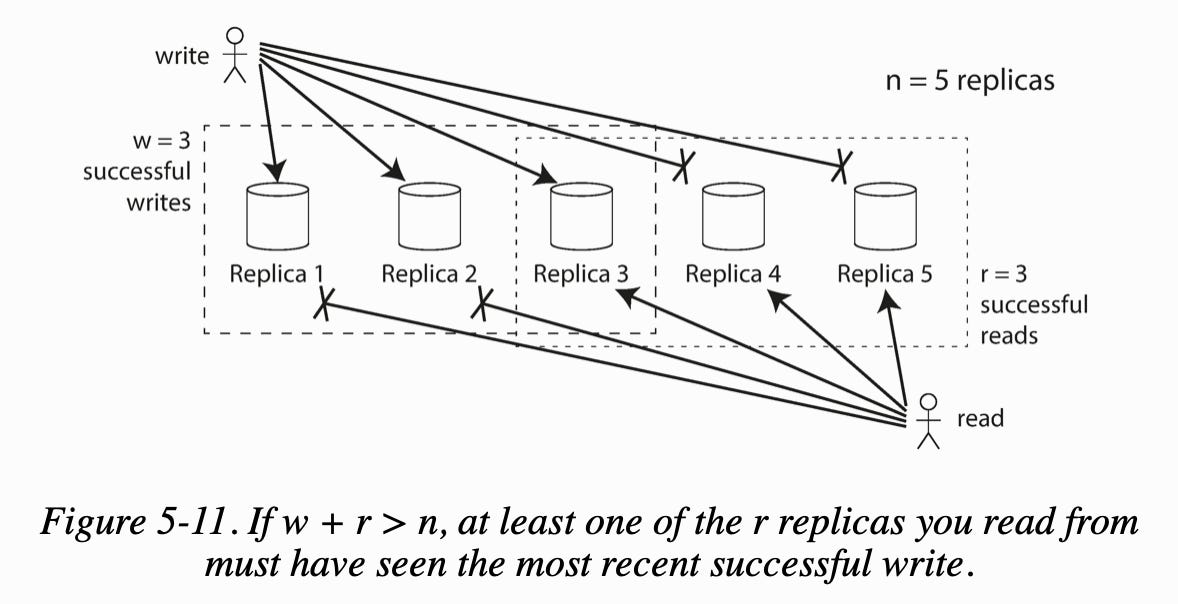
If there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. As long as w + r > n, we expect to get an up-to-date value when reading. The quorum is the minimum number of votes to be valid.
A common choice is to make n and odd number (typically 3 or 5) and to set w = r = (n + 1)/2 (rounded up).
Note that n does not refer to the number of nodes in the cluster, it is the number of nodes that any given value must be stored on (number of replicas).
Sloppy quorum are quorums where writes and reads still require w and r successful responses, but those may include nodes that are not among the designated n replica nodes for a value. They can be non-replica nodes in the cluster.
Once the network interruption is fixed, any writes are sent to the appropriate replica nodes. This is hinted handoff.
Sloppy quorums are useful for increasing write availability: as long as any w nodes are available, the database can accept writes.
Handling Concurrent Writes and the Happens-Before Relationship
Whether one operation happens before another operation is the key to defining what concurrency means. We can simply say that to operations are concurrent if neither happens before the other. Either A happened before B, or B happened before A, or A and B are concurrent.
The server can determine whether two operations are concurrent by looking at the version numbers and allow the client to perform a merge.
Exact time does not matter for defining concurrency, two operations are concurrent if they are both unaware of each other, regardless of the physical time which they occurred.
We also need a version number per replica as well as per key. Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas.
The collection of version numbers from all the replicas is called a version vector.
Conclusion
This covers the replication of data across multiple machines. We’ve looked at the three ways to do this: Leader-Based Replication, Multi-Leader Replication, and Leaderless Replication. Stay tuned as we’ll look at the partitioning of data in distributed systems next. Feel free to share this article if you liked it!