

Why Database Transactions Are Such A Great Idea
Why Database Transactions Are Such A Great Idea
Chapter 7 of Designing Data Intensive Applications: Transactions

Welcome to the 10% Smarter newsletter. I’m Brian, a software engineer writing about tech and growing skills as an engineer.
If you’re reading this but haven’t subscribed, consider joining!
Transactions are one of the fundamental ideas in databases. They enable safe semantics for applications and developers. But what are they and how do you use them? Let’s dive in and find out.
What are Transactions?
Transactions group multiple reads and writes into one operation that rolls back everything if any step fails (all succeed or all fail). It sacrifices performance for safety guarantees.
To write a transaction in MySQL or Postgres, you can write:
BEGIN TRANSACTION;
-- Your queries
COMMIT;Unlike relational databases such as MySQL or Postgres, NoSQL database choose to forgo transactions for greater scalability.
What Do Transactions Protect Against?
Transactions protect against:
Database software or hardware failure in the middle of a write.
Application crashes midway through series of operations.
Network failures that cuts off application from a database or one database node from another.
Multiple clients writing to the database at same time (overwriting each other).
Client reading partially updated data.
Race conditions with weird bugs.
How can transactions enable safety against these failures? Transactions follow a set of properties known as ACID that make them safe.
The ACID Properties
ACID stands for Atomicity, Consistency, Isolation, and Durability.
Atomicity refers to the ability to abort a transaction on error and have all the writes from the transaction discarded. It can then be safely retried.
Consistency means your applications must always be in good state. Your application will have invariants on your data that must always be true. Consistency is actually a property of the application but transactions enforce those rules.
Isolation in ACID means serializability. Concurrently executing transactions are isolated from each other such that each transaction seems to be the only transaction running on the entire database and the result seems like it was ran serially (one after the other).
Durability means once a transaction is committed, any data that has been written will not be forgotten, even if there is a hardware failure or the database crashes.
In a single-node database, this means the data has been written to hard drive. A write-ahead log is also used for recovery. In a replicated database, this means the data has been successfully copied to some number of nodes.
It’s important to note that perfect durability does not exist. If all the hard disks and backups are destroyed at the same time such as a power outage or a bug that crashes every node, there's nothing the database can do to save you.
Serializability and Isolation
Why do we care about serializability and isolation? They can help mitigate concurrency issues (e.g. race conditions), which happen when one transaction reads data, while another transaction modified data, or when two transactions both modify the same data.
Let’s look at some different isolation levels.
Serializable Isolation
Serializable Isolation is the strongest form of isolation. Concurrently executing transactions are isolated from each other and appear to be ran serially (one after the other).
Serializable isolation has a performance cost. It's common for systems to use weaker levels of isolation.
Read Committed Isolation
Next is Read Committed Isolation, an isolation level that guarantees no dirty reads and no dirty writes.
Dirty Reads: When a transaction is able to read uncommitted data from another transaction.
Dirty Writes: When a transaction is able to overwrite uncommitted data from another transaction.
Most databases prevent dirty writes by using row-level locks that hold the lock until the transaction is committed or aborted. Only one transaction can hold the lock for any given object.
On dirty reads, requiring read locks do not work well. One long-running write transaction can force many read-only transactions to wait. Instead, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
One issue of Read Committed Isolation is read skew. Read skew means that you might read the value of an object in one transaction before a separate transaction begins, and when that separate transaction ends, that value has changed into a new value.
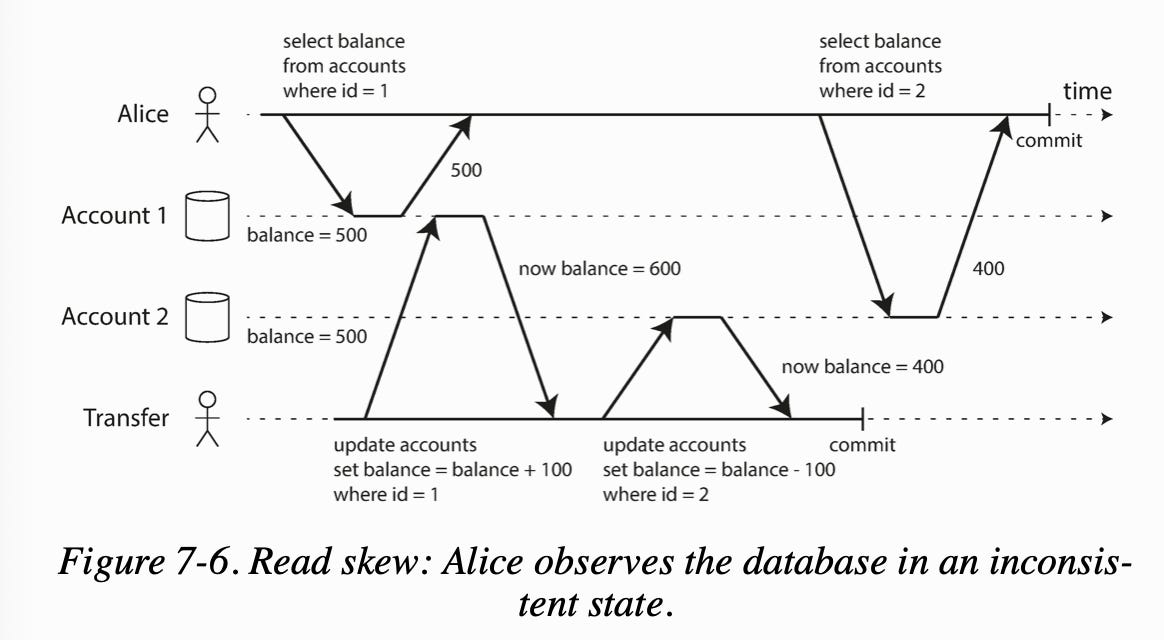
For example, say Alice has $1,000 in two bank accounts. If she does two reads, but a transfer transaction happened concurrently, she could read one account with $500 and one with $400 for only $900.
This is an issue for long running operations with transactions still happening such as backups and analytics queries.
Snapshot Isolation
To prevent read skew, each transaction reads from a consistent snapshot of the database (snapshot isolation). Write locks are used to prevent dirty writes. To prevent dirty reads, and avoid blocks writes, the database keeps multiple committed versions of objects known as multi-version concurrency control or MVCC.
Lost Updates
However, both Read Committed and Snapshot Isolation is still vulnerable to Lost Updates. Lost Updates are an issue where a transaction can reads some value from a database, modify it and writes it back (read-modify-write cycle) when another transaction does as well. This can lead to one of the modifications being lost.
To deal with lost updates, there are many strategies:
Atomic Write Operations: these are the simplest solution to lost updates. Here we use atomic operations such as:
UPDATE counters SET value = value + 1 WHERE key = 'foo'; Explicit Locking: where the application explicitly lock objects that are going to be updated.
Detect Lost Updates: if a lost update is detected, the transaction can be aborted and forced to retry its read-modify-write cycle.
Compare and Set: if the current value does not match with what you previously read, the update has no effect.
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content'; Conflict Resolution and Replication: with multi-leader or leaderless replication, compare-and-set do not apply because there is no guarantee of a single up-to-date copy of data. Instead the strategy used is to allow concurrent writes to create several conflicting versions of a value, and let the application resolve and merge the versions.
Write Skew
Write skew can occur if two transactions read the same objects, and then update some of those objects. You get a dirty write or lost update anomaly.
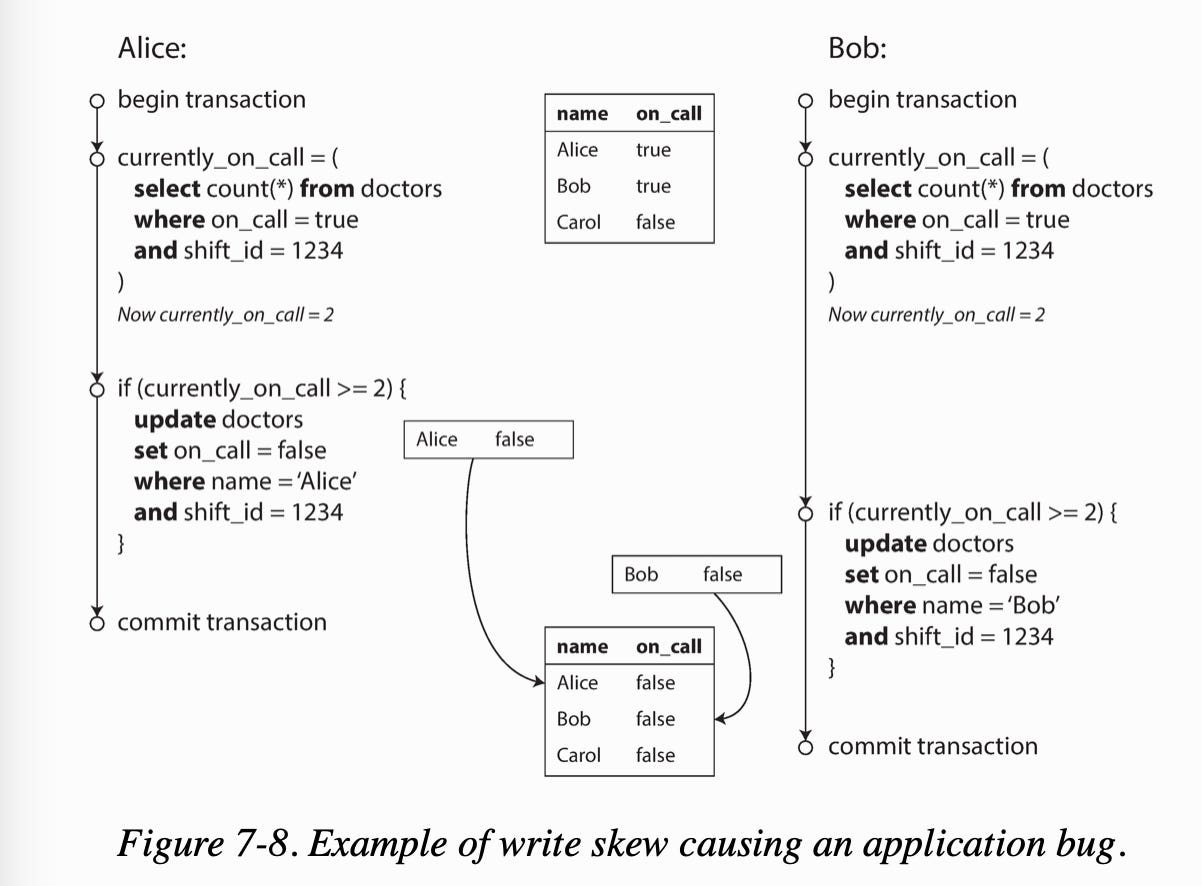
For example, the database is using snapshot isolation, and checks at least two doctors on call. Both transactions can commit successfully, causing an error leaving no doctor on call.
Automatically prevent write skew requires serializable isolation. The second-best option is to explicitly lock the rows that the transaction depends on.
BEGIN TRANSACTION;
SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE;
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;Maybe Serial Isolation is a Good Idea After All
As we’ve seen as these problems, it can often times make sense to use Serial Isolation. Let’s look at the ways we can use Serial Isolation.
Actual Serial Execution
To remove concurrency problems, actual serial execution, execute only one transaction at a time, in serial order, on a single thread.
Two-phase Locking (2PL)
Writers acquire locks and block both writes and readers. It protects against all the race conditions discussed earlier.
The blocking is implemented by having a lock on each object used in a transaction. The lock can either be in shared mode or in exclusive mode. The lock is used as follows:
When a transaction wants to read an object, it must first acquire a shared mode lock. Multiple read-only transactions can share the lock on an object.
When a transaction wants to write an object, it must acquire an exclusive lock on that object.
If a transaction first reads and then writes to an object, it may upgrade its shared lock to an exclusive lock.
After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction.
The two phases are acquiring the locks, and when all the locks are released.
Predicate locks lock all objects that match some search condition including objects that do not yet exist in the database, but which might be added in the future.
Two-phase locking with predicate locks, prevents all forms of write skew allowing for serializable isolation.
SELECT * FROM bookings WHERE room_id = 123 AND end_time > '2018-01-01 12:00' AND start_time < '2018-01-01 13:00';Two-phase locking has some disadvantages though. Deadlock, where a transaction A is stuck waiting for transaction B to release its lock, and vice versa, can occur. Two-phase locking performance is significantly worse than weak isolation. A transaction may have to wait for several others to complete before it can do anything.
Serializable Snapshot Isolation
Serializable Snapshot Isolation provides full serializability and has a small performance penalty compared to snapshot isolation.
This is done by instead of holding locks on transactions, transactions are allowed to continue to execute as normal until the stage where the transaction is about to commit, when it then decides whether the transaction executed in a serializable manner. This approach is known as an optimistic concurrency control.
Two-phase locking is called pessimistic concurrency control because if anything might possibly go wrong, it's better to wait.
Serializable snapshot isolation is optimistic concurrency control technique. Instead of blocking if something potentially dangerous happens, transactions continue anyway, in the hope that everything will turn out all right. The database is responsible for checking whether anything bad happened. If so, the transaction is aborted and has to be retried.
The database knows which transactions may have acted on an outdated premise and need to be aborted by:
Detecting reads of a stale MVCC object version and if any of the ignored writes have now been committed. If so, the transaction must be aborted.
Detecting writes that affect prior reads. SSI uses index-range locks except that it does not block other transactions. If so, it simply notifies the other transactions that the data they read may no longer be up to date.
Conclusion
This covers transactions and their properties that enable safe usage in databases and applications. Stay tuned as we explore the troubles of distributed systems next week. Feel free to share this article if you liked it!